La experiencia de Google con la falla de discos
Fuente(EN-US): http://storagemojo.com/2007/02/19/googles-disk-failure-experience/ (a continuación una breve muy breve traducción del post que toma lo esencial del pdf de 13 hojas…)
Google publicó un muy interesante paper (2007) con el análisis de datos recolectados sobre una población de 100.000 discos pata y sata.
Google encontró resultados sorprendentes en 5 áreas
- La validez de las especificaciones MTBF de los fabricantes
- La utilidad de las estadísticas SMART
- La carga y vida de la unidad
- La edad y las fallas de disco
- La temperatura y las fallas de disco
MTBF de los vendedores y el AFR de Google
Mean Time Between Failure (MTBF) es una medida estadística (Tiempo medio entre falla). Mientras que un vendedor especifica un 300,000 MTBF – común para los consumidores de discos PATA y SATA – lo que ellos están diciendo es que para una amplia población de discos, la mitad de los mismos fallarán en las primeras 300.000 horas de operación. MTBF, por lo tanto, no dice nada sobre cuánto va a durar un disco en particular.

Las especificaiones MTBF de los vendedores
“Debido a que las fallas son muchas veces el resultado de una combinación de componentes (esto es, un disco en particular, con una controladora en particular o cable, etc), . . . un buen número de unidades . . . podrían se consideradas operacionales en diferentes tipos de pruebas. . . situaciones en las que el testeador del disco consistentemente obtiene ok de una unidad que invariablemente fallará en la realidad.”
¿Cuán inteligente es SMART? (How smart is SMART)? No mucho
No mucho, como Google encontró, y muchos en la industria ya lo saben. SMART (Self-Monitoring, Analysis, and Reporting Technology)(Tecnología para el automonitoreo, análisis y reporte) captura datos de error para predecir una falla lo bastante antes así puedes hace una copia de seguridad. Aunque SMART se enfoca en fallas mecánicas, normalmente la falla es electrónica…
Así es que mientras tu disco puede dejar de funcionar sin ningún tupo de aviso en algún momento, ellos encontraron cuatro parámetros SMART donde los errores estan fuertemente correlacionados con la falla del disco:
- scan errors
- reallocation count
- offline reallocation
- probational count
Por ejemplo, luego del primer scan error, encontraron que la unidad era 39 veces mas probable de fallar en los 60 días que en unidades normales. Las otras tres correlaciones son menod directas, pero todavía importantes.
El resultado final: SMART puede advertirte sobre algunos problemas, pero escapa otros, asi que no puedes confiar en él. Entonces no lo hagas. Realiza copias de segudirar y si tienes alguno de estos errores, consigue un disco nuevo.
¿Mucho trabajo = murte temprana? No
Uno podría creer eso, pero los Googlers enconraron poca relación enre la carga de trabajo y las tasas de fallo.
El AFR durante el primer año de mucho uso, es moderadamente alto en su mayoría que en los discos con poca utilización. El grupo de tres años de hecho aparenta un comportamiento opuesto a lo esperado, con poca utilización, los discos tienen un ligero incremento en las fallas promedio que en aquellos de mucha utilización.
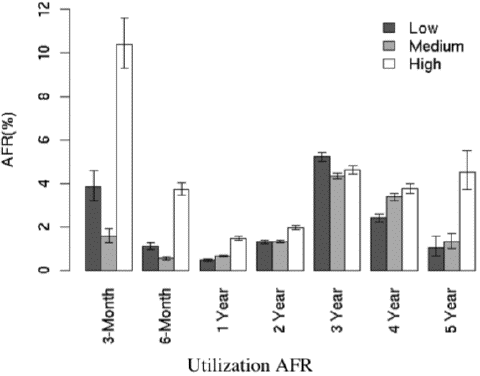
Como se ve en el gráfico, la mortalidad infantil es mucho mayor entre los discos con mucha utilización. Así que sacude tus discos nuevos mientras estan en garantía y no te preocupes por esas tareas de E/S intensivas o hacer backups diarios.
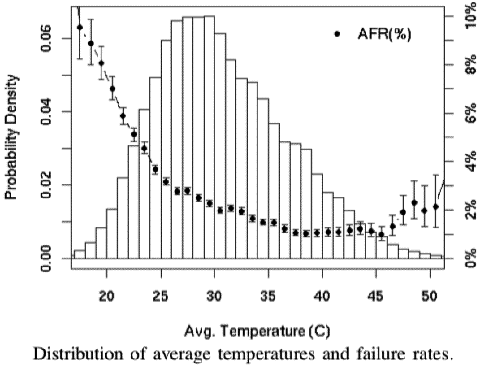
Muerte repentina por calor? No
Uno de los hallazgos más interesantes es la relación entre la temperatura del disco y la mortalidad unidad. El equipo de Google tomó lecturas de temperatura los registros SMART cada pocos minutos durante el período de nueve meses. Como se ve en el gráfico de abajo, las tasas de falla no aumentan cuando aumenta la temperatura media. En temperaturas muy altas se produce un efecto negativo, pero moderado. Aquí está el gráfico del paper:
La edad de la unidad tiene un efecto, pero de nuevo, sólo a muy altas temperaturas, aquí el gráfico:
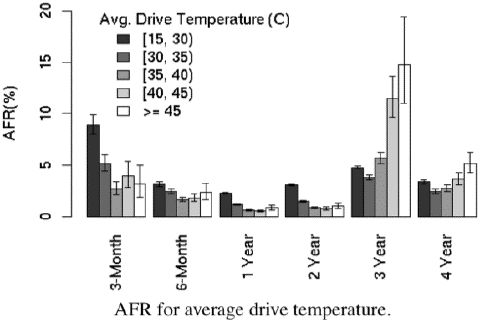
Los Googler Concluyen:
En los rangos de temperatura baja y media, mayores temperaturas no están asociadas con mayores fallas de disco. Este es un hallazgo bastante sorprendente que puede servir a diseñadores de centros de datos o servidores para que tengan mayor libertad que previamente tenían cuando fijaban temperaturas operacionales para equipos que contienen discos.
Buenas noticias para los administradores de los data centers.
StorageMojo dice:
Aquí hay mucho y las implicaciones pueden sorprender.
- Los números de MTBF de disco, pueden significativamente significantly subestimar tasas de fallos. Si planificas con AFR, son 50% más altas que lo que sugiere MTBF, vas a estar mejor preparado.
- Para nosotros usuarios SOHO, considerar reemplazar discos con antigüedad de 3 años o por lo menos ponerse serios sobre BackUp.
- Para los compradores de disco empresariales, deberían reclamar datos reales para respaldar el aclamado MTBF – tipicamente un millon de horas más – para esos discos costosos y ahora mucho menos estudiados.
- SMART le alertará de algunas cosas, pero no de la mayoría, asi que la industria debería venir con algo más útil.
- Los números de carga de trabajo, llaman a pensar sobre la utilidad de arquitecturas como MAID que se apoyan en apagar los discos para aumentar la vida. Los googlers no estudiaron esa aplicación.
- La gente que planifica y vende soluciones de refrigeración, debería replantearse las cosas. Quizás más frio no es siempre mejor. Pero de seguro es más caro.
- Esto da validez el uso de discos para consumidor en centros de datos, porque por primera vez tenemos un estudio de población a gran escala que nunca vimos para discos empresariales.
Etiquetas: Benchmarks, error, Hardware, Reviews
publicadas por miguesmart a la/s
abril 29, 2011
![]()
![]()

0 Comentarios:
Publicar un comentario
Suscribirse a Comentarios de la entrada [Atom]
<< Página Principal